Manga Panel Search with Visual Similarity, Reranking, and VLM Explanation
Published on: Medium
Ever struggled to find that one panel in a manga you vaguely remember?
In this post, I walk through a multimodal RAG system I built for searching and explaining scenes in the manga Frieren: Beyond Journey’s End (Volume 01). The goal is simple but powerful:
Let users search manga using either a visual or textual query and get semantically relevant panels with visual-language model explanations.
For example:
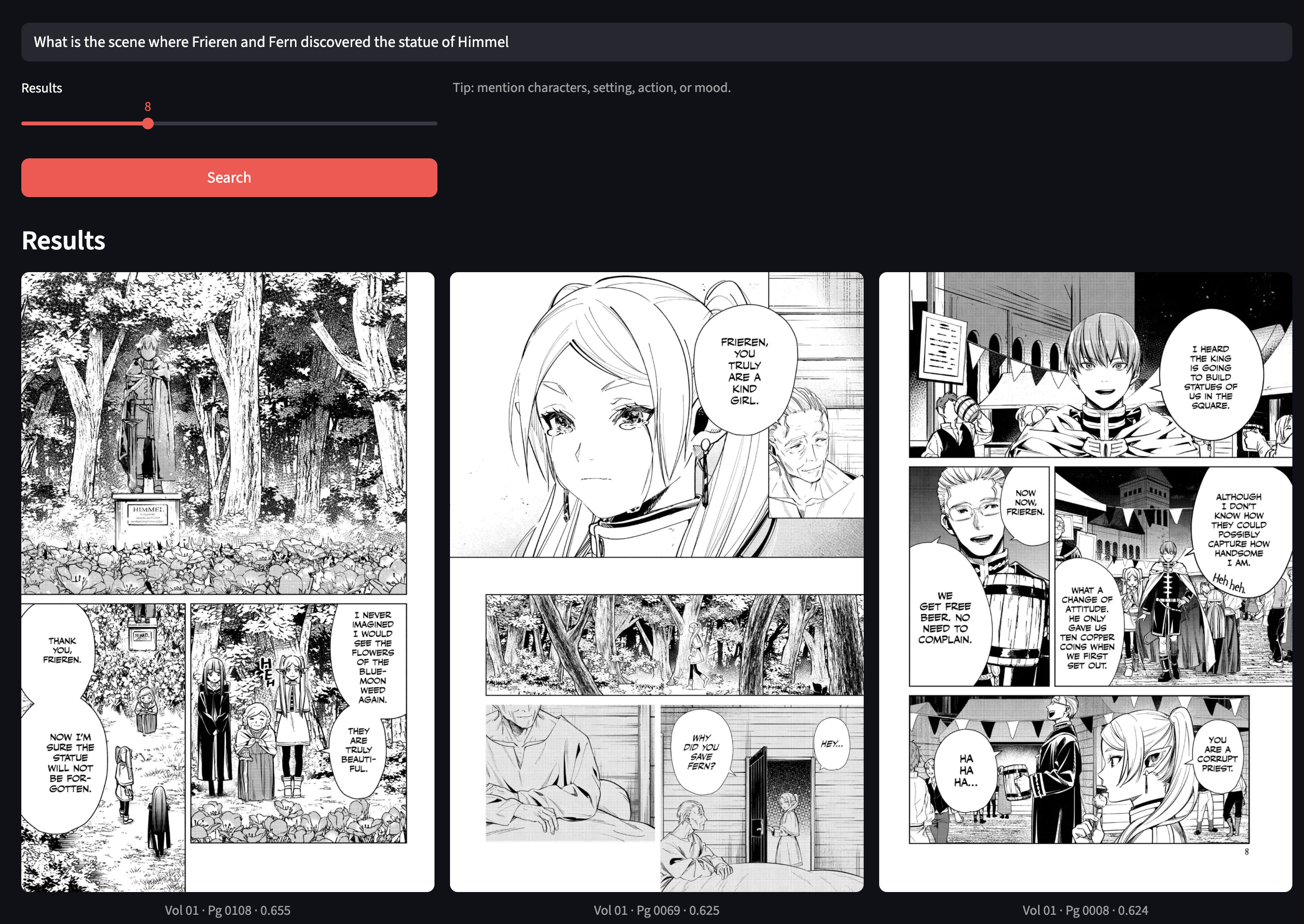
“What is the scene where Frieren and Fern discovered the statue of Himmel?”
should retrieve the exact panel—even if you only describe it.
Why Multimodal RAG?
There are several approaches to visual search in manga or comics. Each has trade-offs. Here's why I chose Multimodal Retrieval-Augmented Generation (RAG):
1. Keyword-Based Search
Using captions, OCR outputs, or manual tags for keyword lookup.
Problems:
- Manga panels often lack text or contain sparse speech bubbles.
- OCR may fail on Japanese/Katakana or artistic fonts.
- Visually significant scenes without text are missed.
2. Visual Similarity (CLIP / CNN + k-NN)
Each image is embedded into a vector, and visually similar panels are returned using cosine similarity.
Pros: Fast and language-independent.
Cons:
- Cannot answer textual queries.
- Visually similar ≠ semantically similar (e.g., same layout but different meaning).
- Lacks context.
3. Caption Generation + Text-Only RAG
Each panel is captioned, and standard text-based RAG is applied.
Pros: Works with traditional RAG pipelines.
Cons:
- Captions are noisy and unreliable.
- Highly sensitive to model quality.
- Different users may describe the same panel differently.
4. Multimodal RAG: Flexible and Intuitive
I opted for Multimodal RAG where both visual and textual queries are embedded in a shared vector space.
- Users can upload an image or type a query.
- Both are embedded using the same model.
- Matches are semantically ranked and optionally reranked with a token-level reranker.
Why it works:
- No need for captions or manual tagging.
- Captures semantic meaning, not just visual layout.
- Supports free-form text and direct visual lookup.
- Allows reranking (e.g., MaxSim) for improved precision.
System Architecture Overview
Here’s the full pipeline:
-
PDFs to PNGs:
PDF volumes converted to page-wise PNGs using PyMuPDF.
-
Embeddings (Jina v3):
Each image embedded into 1024-dim vectors viajinaai/jina-embeddings-v3. -
Vector Store (Qdrant):
Indexed with metadata likevolume,page_number, andimage_path.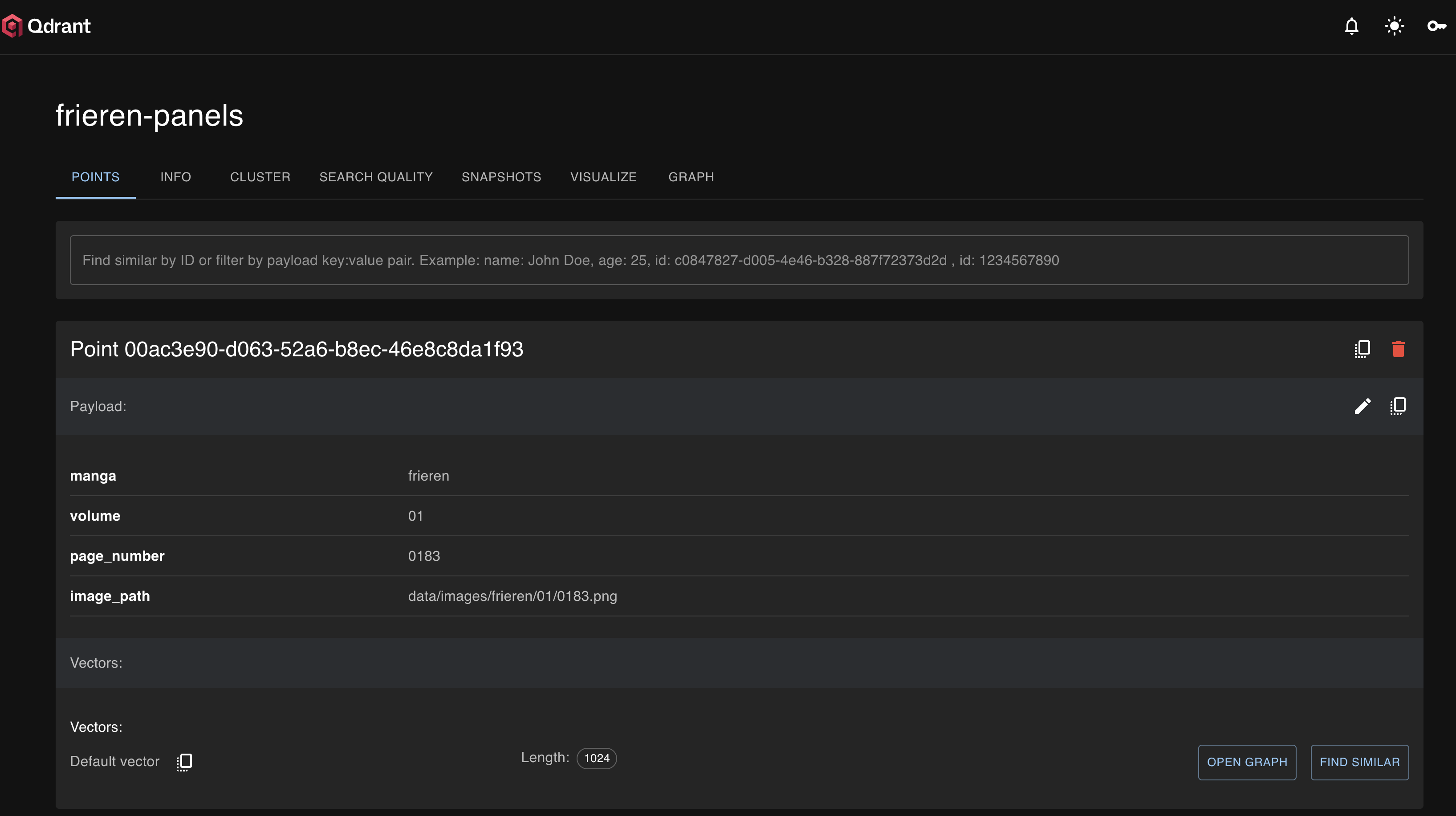
Also, possible to view graph vectors:
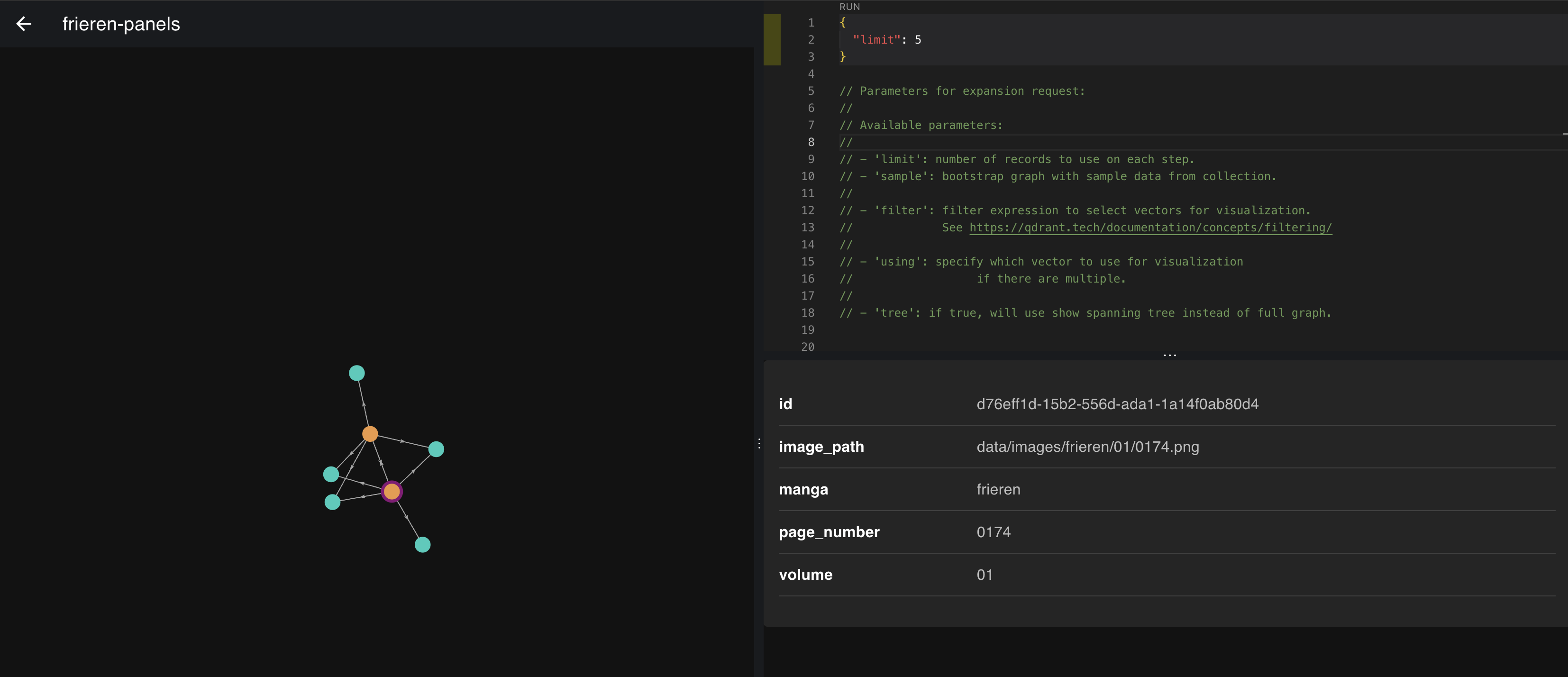
-
Multimodal Search:
- Image → Image: Find visually similar panels.
- Text → Image: Natural language queries return relevant panels.
-
Reranker (MaxSim / ColBERT):
Top-k candidates reranked using token-level similarity. -
Explanation (MiniCPM-V-4):
Selected panels are described using a vision-language model (VLM).
Models Used
| Stage | Model |
|---|---|
| Embedding | jinaai/jina-embeddings-v3 |
| Vector DB | Qdrant |
| Reranker | colbert-ir/colbertv2.0 |
| VLM | openbmb/MiniCPM-V-4 |
MaxSim Reranker for Token-Level Precision
Basic cosine similarity is fast but shallow.
To get truly meaningful matches for textual queries, I added a MaxSim reranker.
How it works:
- Query tokens and visual patches are embedded.
- For each query token, the most similar patch token is selected.
- Final score is the average of these max similarities.
score = mean(max_sim(query_token_i, panel_tokens))
This helps:
-
Disambiguate between visually similar but semantically different panels.
-
Improve retrieval quality for questions like: “What was Frieren doing in this scene?”
To support patch-level embedding, I used clip-vit-base-patch16 as the encoder and reranked with colbertv2.0.
Explaining Panels with MiniCPM-V-4
After retrieving a panel, I wanted to generate natural-language explanations. For this, I integrated MiniCPM-V-4 —a lightweight, high-performance vision-language model.
Use Cases:
-
Descriptive Prompts: “What’s happening in this panel?” “Describe the characters and setting.”
-
Targeted Questions: “Who is Frieren talking to here?” “What emotion does this scene convey?”
The model generates contextual answers using character posture, facial expressions, and background features.
Demo: Examples
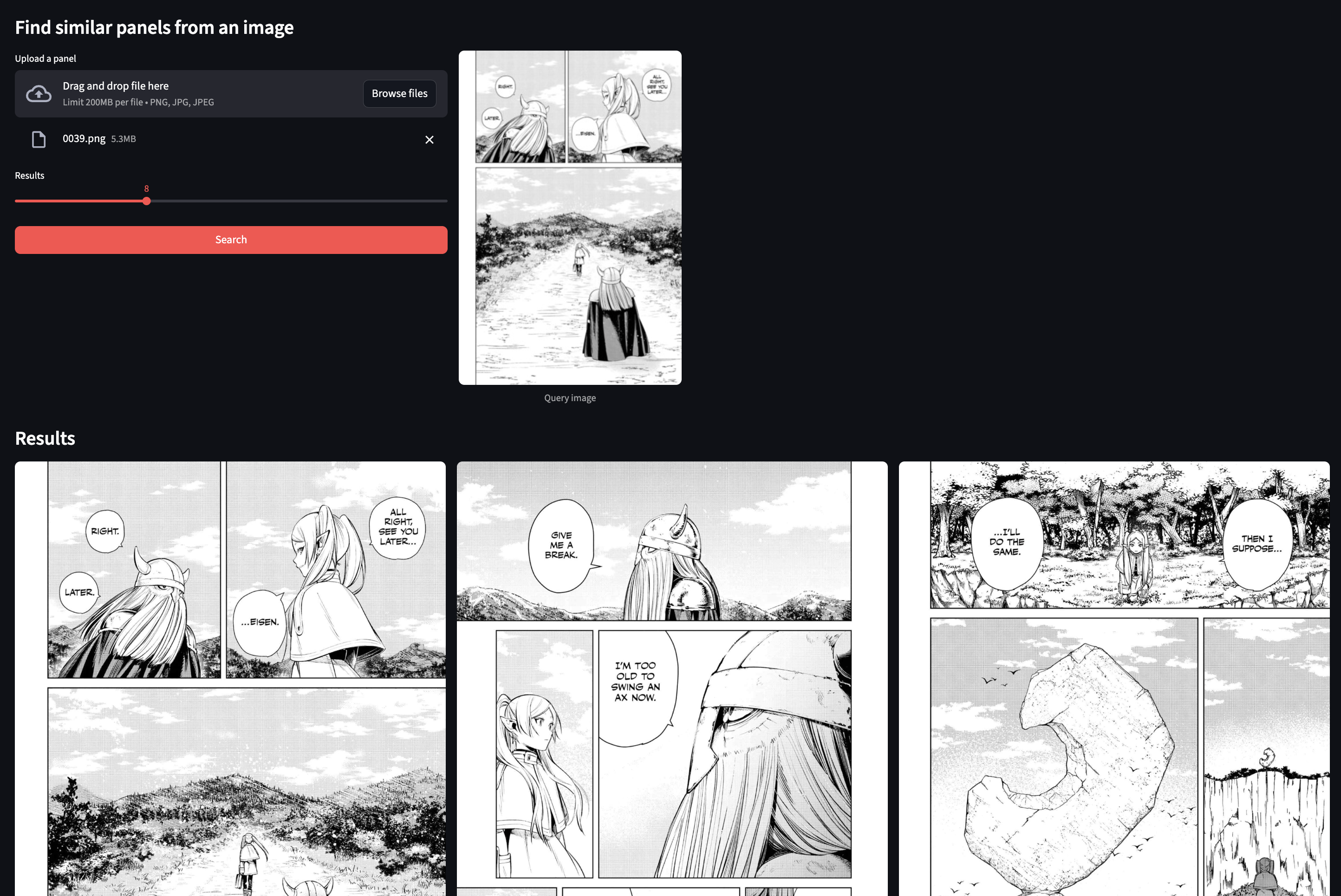
###Visual → Visual Search:

Text → Visual (RAG + MaxSim)
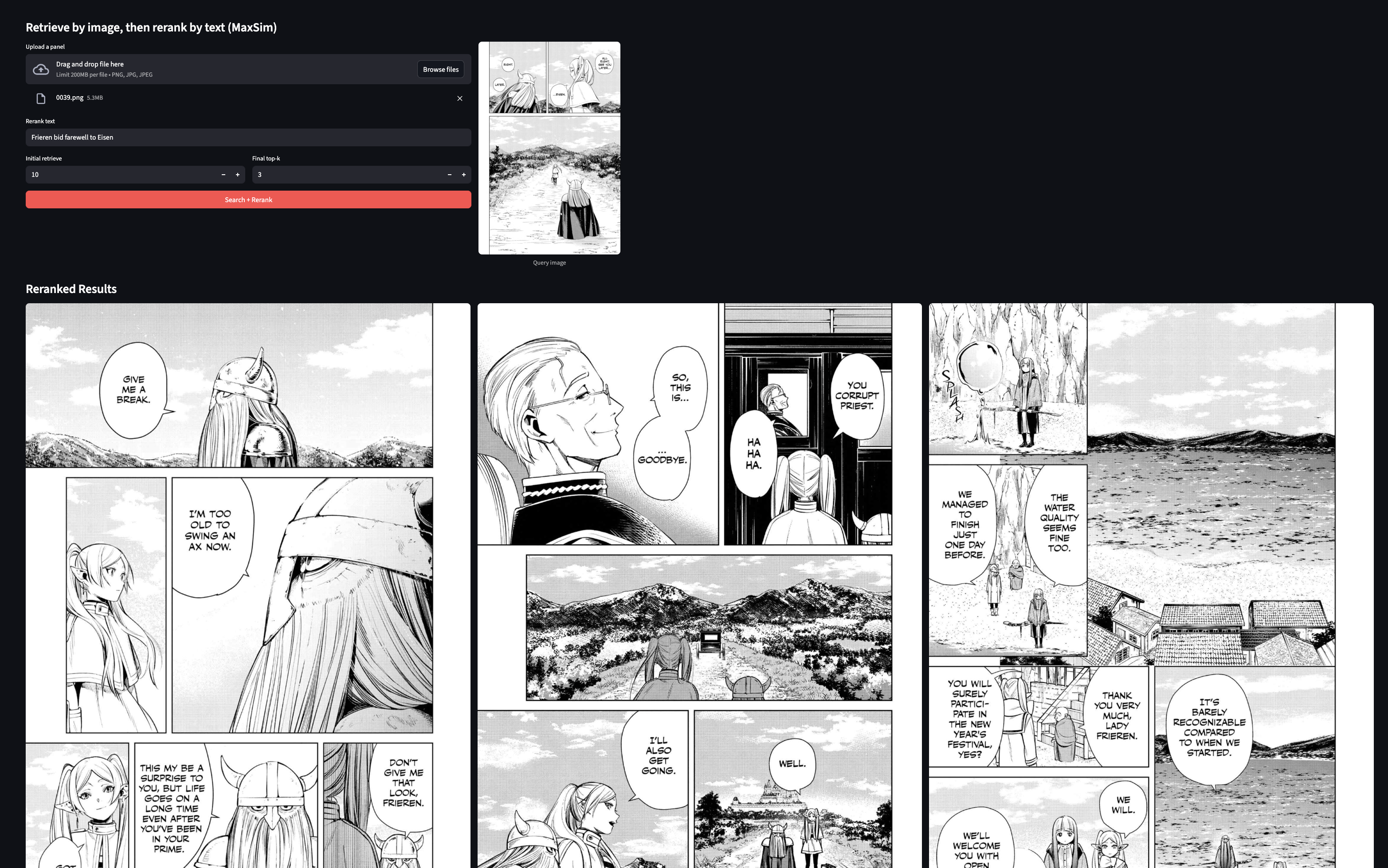
Query: “graveyard scene” → Top matches reranked based on token-level semantic fit.
VLM Explanation:
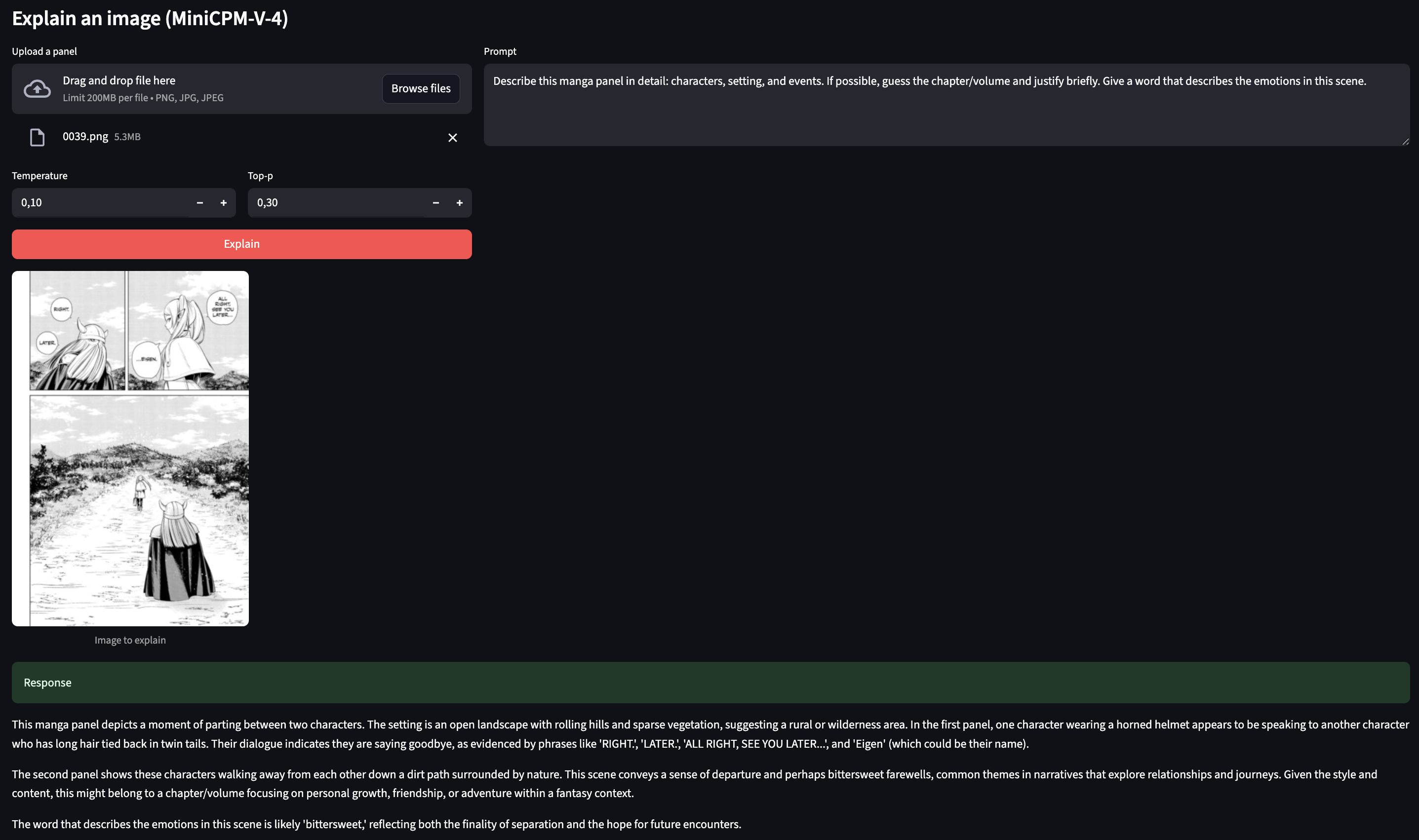
Prompt: Describe this manga panel in detail: characters, setting, and events. If possible, guess the chapter/volume and justify briefly. Give a word that describes the emotions in this scene.
Output:
This manga panel depicts a moment of parting between two characters... The word that describes the emotion in this scene is bittersweet.
Insights
-
Visual RAG outperforms traditional text-only search in manga scenarios.
-
Token-level reranking (MaxSim) significantly improves semantic precision.
-
Embedding both text and images in a shared space (Jina v3) offers great flexibility.
-
Qdrant supports fast multimodal similarity search and metadata filtering.
-
MiniCPM-V is lightweight but surprisingly capable of nuanced explanations.
-
Turkish queries don’t work well yet—VLMs still struggle with non-English prompts.
-
Some character names and letters may be misread due to patch overlap.
Future Work
Some exciting enhancements ahead:
-
Panel Segmentation: Detect and crop individual panels using YOLO or SAM instead of using full pages.
-
Semantic Tagging: Add character recognition, emotion detection, and scene classification.
-
Narrative Graphs: Build a timeline of events by tracing character trajectories and interactions.
Conclusion
Finding and understanding a specific manga scene shouldn't require flipping through 200 pages. With Multimodal RAG + VLM, we can now:
-
Retrieve panels using either images or free-text
-
Rerank results with token-level semantics
-
Explain scenes in natural language
The architecture is fast, extendable, and fully open source. Check out the code on GitHub and explore your favorite manga like never before.
GitHub repo: [https://github.com/rabiaedayilmaz/manga-multimodal-rag]